Ανωνυμοποίηση μικροδεδομένων
Σε αυτήν την ενότητα μπορείτε να ενημερωθείτε διεξοδικότερα για την περιγραφή και την ανάλυση των βημάτων και των σταδίων ανωνυμοποίησης των μικροδεδομένων στο πλαίσιο της μεθοδολογίας που έχει υιοθετηθεί επίσημα από τη Eurostat.
Διαδικασία ανωνυμοποίησης
-
Κείμενο
Στο πλαίσιο της υλοποίησης των αναγκών της Πράξης για την Ενίσχυση της Δημόσιας Στατιστικής Πληροφόρησης η Ομάδα Έργου εστίασε στο μεθοδολογικό πλαίσιο της Eurostat και το υιοθέτησε, ώστε να προβεί στην ανωνυμοποίηση των μικροδεδομένων. Πρακτικά η Ομάδα Έργου του ΕΚΤ αξιοποίησε το μεθοδολογικό πλαίσιο της Eurostat και προέβη σε μικρές αναπροσαρμογές, ώστε να είναι όσο το δυνατόν πιο άρτια τεχνικά η διαδικασία της ανωνυμοποίησης των μικροδεδομένων των Στατιστικών Ερευνών του ΕΚΤ. Πιλοτικά η πρώτη εφαρμογή έγινε στη Στατιστική Έρευνα της Καινοτομίας των Επιχειρήσεων (CIS) για τα έτη 2014-2016, 2016-2018 και 2018-2020. Η πρόσθετη αξία της Ομάδας Έργασίας του ΕΚΤ αναφορικά με τη συγκεκριμένη δραστηριότητα έγκειται στην τήρηση της ισορροπίας μεταξύ της εκχωρούμενης πληροφορίας χωρίς να προσδιορίζεται φωτογραφικά η ταυτότητα του εκχωρητή δεδομένων και να χάνεται σημαντικό τμήμα πληροφορίας. Η εν λόγω ενέργεια εντάσσεται στο πλαίσιο της ανοικτότητας και της ευρύτερης διάχυσης και βέλτιστης αξιοποίησης των στατιστικών δεδομένων μέσω λόγου χάρη της επανάχρησής τους.
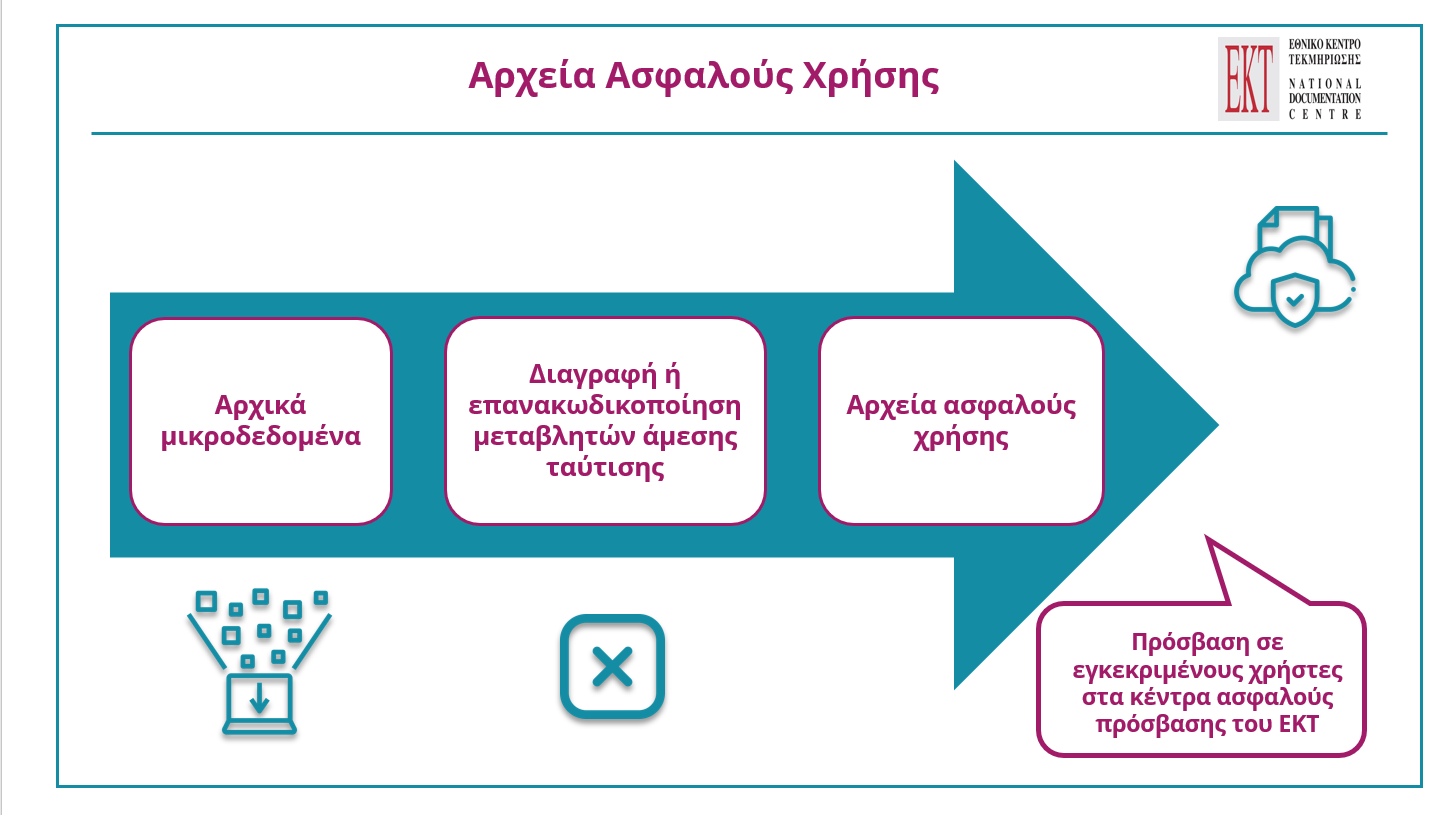
Σχεδιάγραμμα: Αρχεία ασφαλούς χρήσης
Στο επόμενο σχεδιάγραμμα νοηματοδοτείται, παρουσιάζεται και σχηματοποιείται η μελλοντική διαδικασία πρόσβασης των ερευνητών στα ανωνυμοποιημένα μικροδεδομένα στην αναβαθμισμένη υποδομή συγκείμενων δεδομένων του ΕΚΤ μέσα από μια σειρά συγκεκριμένων βημάτων στο πλαίσιο συγκεκριμένης μεθοδολογίας που υιοθετήθηκε και εφαρμόστηκε πολλάκις επιτυχώς από την ΕΛΣΤΑΤ, την Eurostat και τον ΟΟΣΑ.
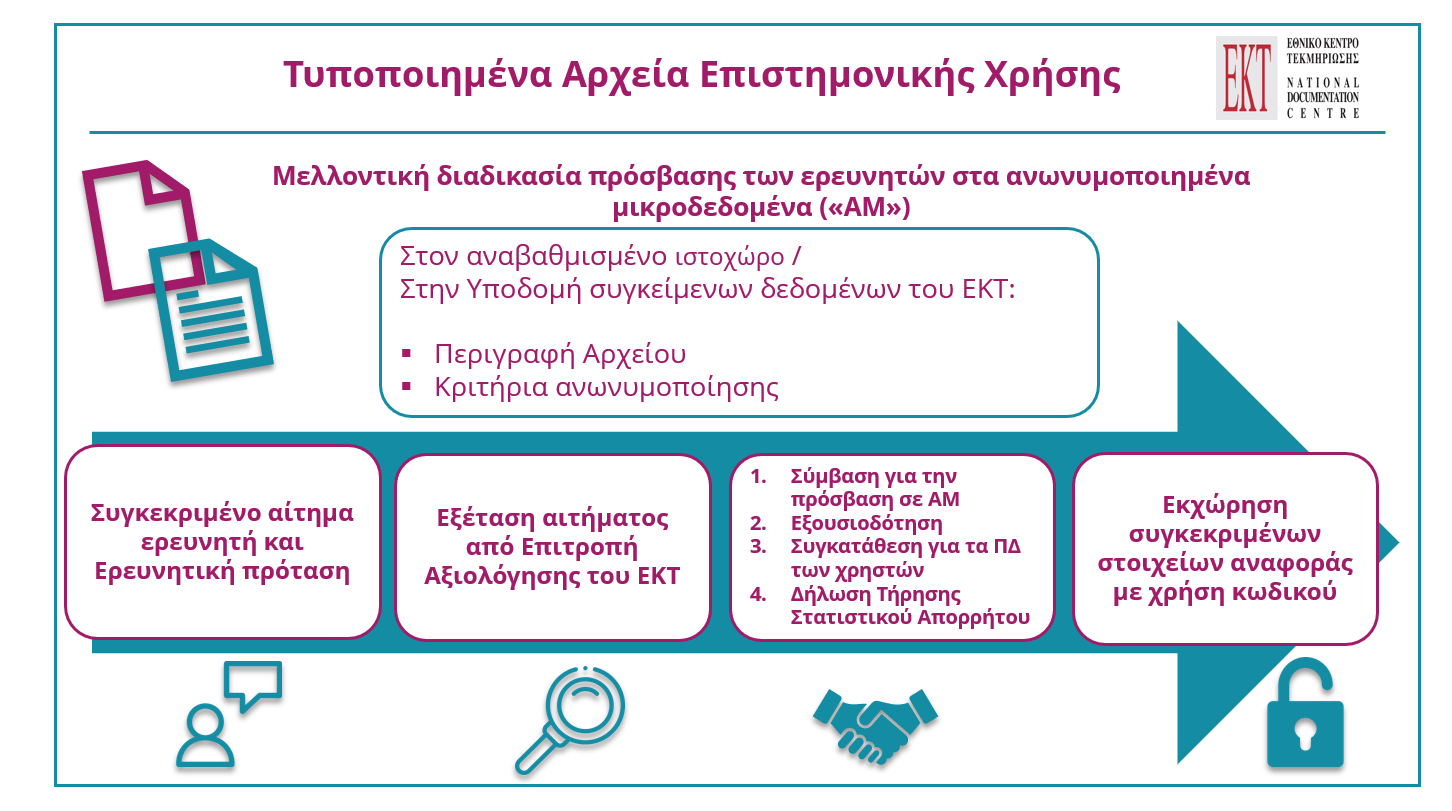
Σχεδιάγραμμα: Τυποποιημένα αρχεία επιστημονικής χρήσης
Στο πλαίσιο της επιτυχούς εφαρμοσιμότητας σε άλλα αυστηρά μεθοδολογικά πλαίσια εκτιμάται ότι θα διευκολύνει τους δυνητικούς χρήστες και αποδέκτες των υπηρεσιών του ΕΚΤ στο πλαίσιο των εκάστοτε ερευνητικών τους εγχειρημάτων αναφορικά με τα δεδομένα, μικροδεδομένα και μεταδεδομένα ΕΤΑΚ. Ο ενδιαφερόμενος αναγνώστης μπορεί να ανατρέξει στις επόμενες ενότητες και στο παράρτημα, για να δει συγκεκριμένα τις φόρμες, όπως η σύμβαση, η εξουσιοδότηση, η δήλωση τήρησης στατιστικού απορρήτου και η δήλωση για τα προσωπικά δεδομένα.
-
Κείμενο
Συγκεκριμένα για τη μέθοδο ανωνυμοποίησης των μικροδεδομένων της Στατιστικής Έρευνας για την Καινοτομία (“CIS”), που προορίζονται για επιστημονική χρήση, η μεθοδολογία του ΕΚΤ βασίστηκε σε τρεις θεμελιώδεις αρχές:
- Την τήρηση της εμπιστευτικότητας των δεδομένων. Σημειώνεται εδώ ότι ο μηχανισμός πρόσβασης στα μικροδεδομένα για τους ερευνητές per se προσφέρει ένα επίπεδο προστασίας για τα μικροδεδομένα,
- Την επιστημονική χρήση των δεδομένων, η οποία προτεραιοποιείται. Αυτό πρακτικά σημαίνει ότι θα πρέπει να αποφεύγεται η διαγραφή ή η «διαταραχή» των δεδομένων όσο το δυνατόν περισσότερο και
- Στις περιπτώσεις που οι τροποποιήσεις και οι μετασχηματισμοί στα δεδομένα δεν είναι δυνατόν να αποφευχθούν, θα πρέπει να γίνονται με τέτοιο τρόπο, ώστε να συνυπολογίζεται η στατιστική ανάλυση των δεδομένων από τους ερευνητές.
Ακολουθεί η διαδικασία «κωδικοποίησης» και προτυποποίησης της μεθοδολογίας της ανωνυμοποίησης των μικροδεδομένων σε τρία (3) συγκεκριμένα βήματα, τα οποία διαμορφώνονται ως εξής:
Βήμα 1:
Ανωνυμοποίηση των δεδομένων της Στατιστικής Έρευνας «Καινοτομία Επιχειρήσεων», ακολουθώντας την επίσημη μεθοδολογία της Eurostat [1].
Βήμα 2:
Προσαρμογή της μεθοδολογίας για τη Στατιστική Έρευνα «Έρευνα και Ανάπτυξη» (R&D) κατά το ισχύον πρότυπο για την Έρευνα στην «Καινοτομία Επιχειρήσεων» (CIS) και πιθανόν μελλοντική επέκτασή της, ώστε να επιτυγχάνεται ανωνυμοποίηση και άλλων στατιστικών μονάδων εκτός της επιχείρησης, δηλαδή των ατόμων.
Βήμα 3:
Δημιουργία μεθοδολογίας, σχεδιασμός και υλοποίηση αλγορίθμων για την ανωνυμοποίηση των υπόλοιπων ερευνών, ανάλογα με τα χαρακτηριστικά τους (π.χ. επανεπισημαίνεται ότι στους διδάκτορες και το εξειδικευμένο ανθρώπινο δυναμικό η στατιστική μονάδα είναι ο άνθρωπος και όχι η επιχείρηση) [2].
Η ανωνυμοποίηση μπορεί να διαχωριστεί σε δύο κατηγορίες, την «πλήρη» και τη «μερική». Ως «πλήρης ανωνυμοποίηση» ορίζεται η διαδικασία επεξεργασίας δεδομένων των ερευνών, προκειμένου να αποκαλύπτονται με άμεσο ή έμμεσο τρόπο οι στατιστικές μονάδες (λ.χ. επιχειρήσεις, λοιποί οργανισμοί και μεμονωμένα υποκείμενα), στις οποίες αναφέρονται τα δεδομένα. Από την πλήρη ανωνυμοποίηση μπορούν να προκύψουν αρχεία δημόσιας χρήσης.
Στη «μερική ανωνυμοποίηση» υπάρχει μειωμένος κίνδυνος αποκάλυψης των στατιστικών στοιχείων με διεξοδικότερη επεξεργασία των μικροδεδομένων. Από τη μερική ανωνυμοποίηση μπορούν να προκύψουν αρχεία επιστημονικής χρήσης και αρχεία ασφαλούς χρήσης.
Στο ακόλουθο σχεδιάγραμμα νοηματοδοτείται, παρουσιάζεται αναλυτικά και σχηματοποιείται η διαδικασία διαχωρισμού και κατηγοριοποίησης των τύπων αρχείων των ανωνυμοποιημένων μικροδεδομένων, καθώς επίσης και οι κυριότερες διαφοροποιήσεις μεταξύ της πλήρους και μερικής ανωνυμοποίησης των μικροδεδομένων. Επιπλέον, αποτυπώνονται σχηματικά τα εμπιστευτικά στοιχεία για επιστημονικούς σκοπούς και τα αρχεία δημόσιας χρήσης.
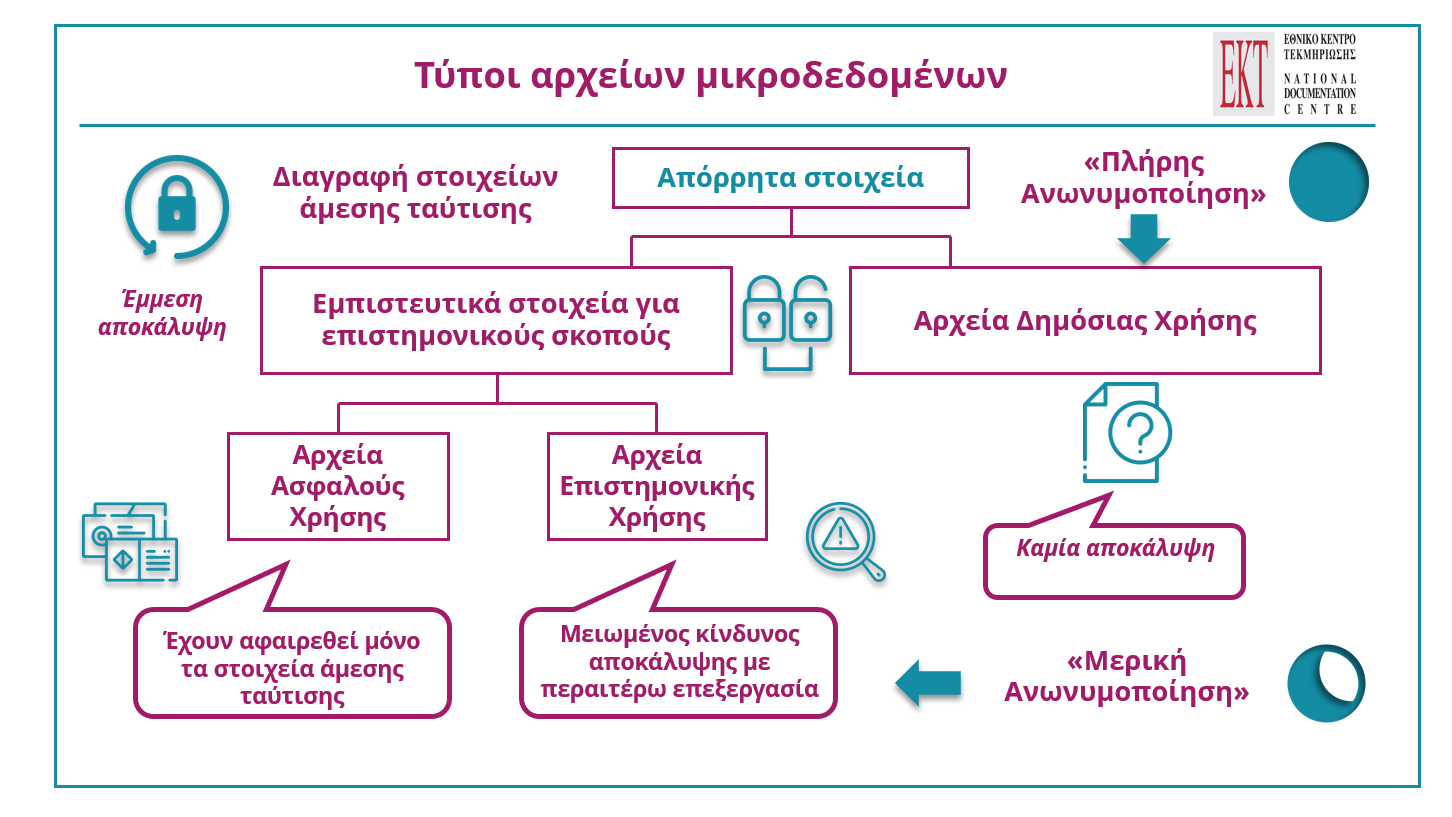
Σχεδιάγραμμα: Τύποι αρχείων μικροδεδομένων
Η πιο συνηθισμένη στρατηγική που ακολουθείται στο πλαίσιο της διαδικασίας της ανωνυμοποίησης είναι η επανακωδικοποίηση δια της «διαταραχής» των μεταβλητών, η οποία ουσιαστικά συνήθως συνιστά συνειδητή και προτιμητέα επιλογή των κατηγορικών έναντι των συνεχών μεταβλητών. Ουσιαστικά ακολουθείται μια διαδικασία, σύμφωνα με την οποία οι αρχικές συνεχείς μεταβλητές επανακατηγοριοποιούνται ή/και συγχωνεύονται σε κατηγορίες με λιγότερο λεπτομερή πληροφορία, στην προσπάθεια να μην εντοπίζεται άμεσα ή έμμεσα πληροφορία που ενδεχομένως να «φωτογραφίζει» συγκεκριμένες στατιστικές μονάδες κατά τον προαναφερθέντα τρόπο.
[1] Eurostat (2021). Description of the dataset. CIS for scientific purposes. Διαθέσιμo εδώ.
[2]Ο ενδιαφερόμενος αναγνώστης μπορεί να διαβάσει το European Commission - Eurostat – Unit G: European Businesses (2021). Anonymisation of CIS 2016 Microdatasets: Description of rules and outputs αν ενδιαφέρεται να εντρυφήσει στην εξέλιξη της διαδικασίας της ανωνυμοποίησης των μικροδεδομένων στο πλαίσιο της έρευνας για την Καινοτομία (CIS) από τη Eurostat.